20x Speed Boost: How We Supercharged Our Idea Generation with Llama3 on Groq

University of Waterloo, Quantum Building
We sped up our Blog Idea generation by 20x during a late night hackathon, here’s how ↴
What is Burgundy and Background
First a bit of background: in April of 2023, we launched an AI-enabled software service called Burgundy. This product helps digital content teams generate blog ideas more efficiently and collaborate more effectively as a team. We used the best in class API available to us at the time (that is, first we used 3.5-turbo, then GPT-4) to create the functionality. The software worked like “magic” as it was described by the people we demoed it to.
However, content generation was slow, especially with GPT4, the state-of-art quality large-language model GPT4. To make the users’ experience more palatable, we halved the number of blog ideas generated and drastically reduced the amount of content per blog post from long-form post to a summary of the idea, an abstract if you will. However, the process of generating a new content plan (that is, 5 blog ideas and abstracts) took well over 2-3 minutes if we used GPT4. We switched back to GPT3.5 and made peace with the fact that Burgundy, the Content Plan Co-pilot, will take about a minute to finish.
Here’s a video of Burgundy in Action before the speed up (generation starts at min 4:55, you can see the facial expressions while waiting for it to finish in the sped-up video! Actual footage would have been about 2 minutes of waiting for the generation):
“What are the new use cases that this architecture enables by speeding up LLM generation by orders of magnitude”
Fast forward to April 2024: I was inspired by what Groq’s Head of Cloud said: “with Groq’s orders of magnitude speed up, what are the new use cases for LLMs”. We as a team decided to upgrade our Burgundy to use Groq’s API. With the release of Llama3, the quality of this open-source model is at a great place, certainly exceeding our requirements for our content-idea-generation co-pilot. Therefore, we had nothing to lose from the quality of content perspective and only expecting gains in terms of speed up.
The AI Infrastructure Migration
The following paragraph is technical, related to the migration which was extremely smooth, and the final paragraphs are about the results. First the technical aspect.
To give credit where it’s due, OpenAI as the trailblazer, has set the standards in the Large-Language Model (LLM) space. Namely, the Chat API signatures, and as a result the Python wrapper APIs. Most LLM providers now follow the same convention, namely:
import os
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Explain the importance of fast language models",
}
],
model="mixtral-8x7b-32768",
)
print(chat_completion.choices[0].message.content)
This allowed us to convert our application to use Groq, by simply applying the following changes:
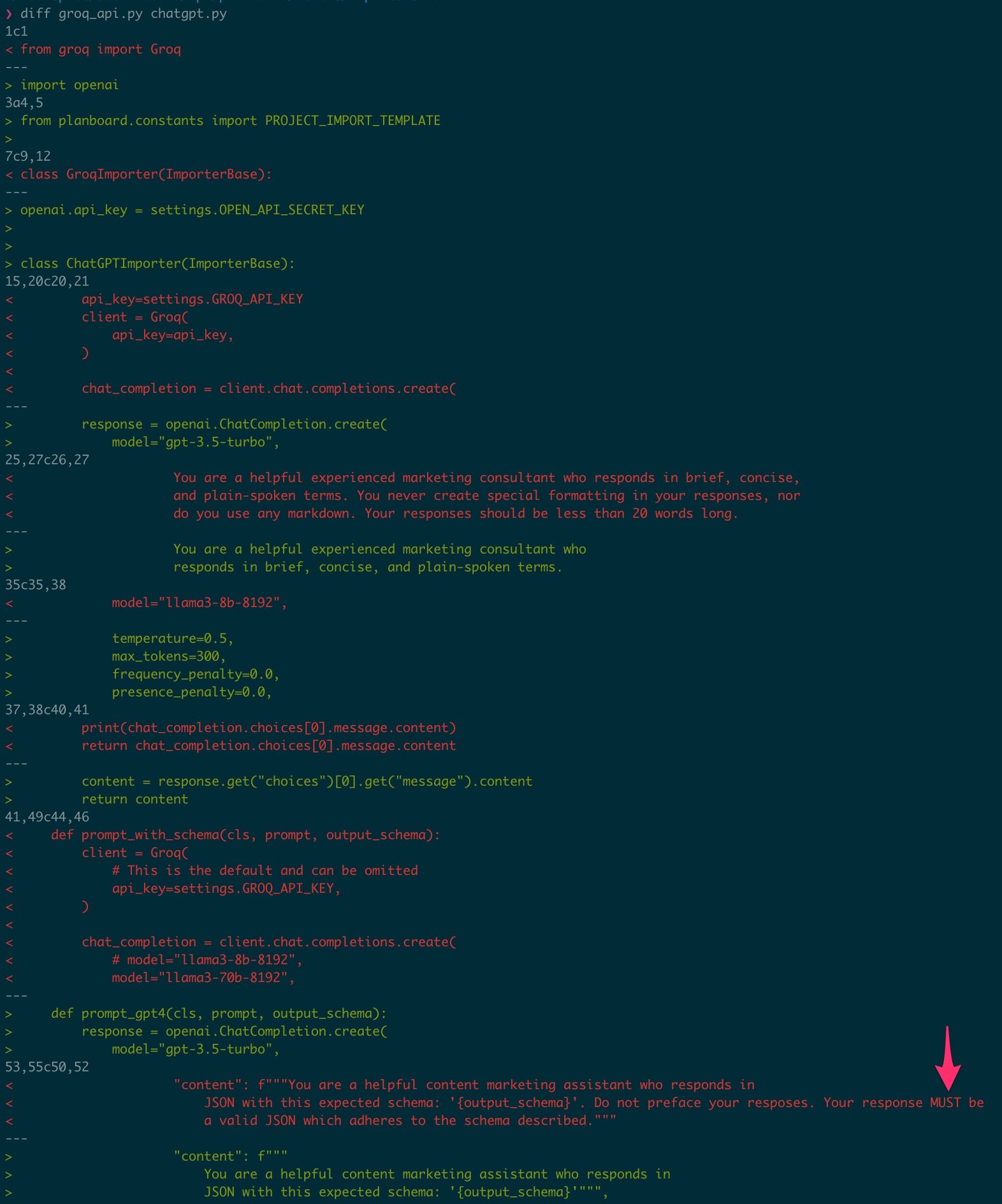
About 70-lines difference in a code base of about 3400 lines of code:
~/workspace/askburgundy.com/api $ loc
---------------------------------------
Language Files ... Code
---------------------------------------
Python 104 ... 3385The Results of Migration to Groq’s LPU Infrastructure
After the switch over, we were able to get results in 2-5 seconds! This is a speed up of 20-60x but beyond the speed up factor, the actual amount of time a user has to wait is important. While waiting a few seconds is still not perfect, we are in an acceptable range. (Google Search is the golden standard for user-experience: results within 200-300ms)
See the application in action in this 1 minute video:
Thanks to Groq’s inference-specific silicon design (LPUs) and infrastructure, we are able create a good user-experience from a speed and responsiveness point of view. And from a quality of content-point of view, create a “magical” user-experience.
We hope you enjoyed reading this case-study. If you’d like to discuss a project which could benefit from our expertise in AI, Large Language Models and the phenomenal user-experiences this technology enables, please contact us as we are always happy to discuss this topic.

Helping you take your next step
Sahand Sojoodi from Integral meets with business and technology leaders charged with making complex tech investment decisions for their businesses.
Whether you’re at the beginning of your journey or getting close to implementing AI and Large Language Models, ask how we can help.